Unit 1
Lexical Analysis
Introduction to Compiling
INTRODUCTION OF LANGUAGE PROCESSING SYSTEM
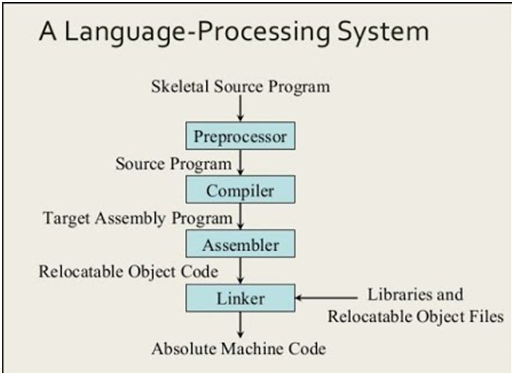
Preprocessor:-
· A preprocessor produce input to compilers. They may perform the following functions.
1) Macro processing: A preprocessor may allow a user to define macros that are short hands for longer constructs.
2) File inclusion: A preprocessor may include header files into the program text.
3) Rational preprocessor: these preprocessors augment older languages with more modern flow-ofcontrol and data structuring facilities.
4) Language Extensions: These preprocessor attempts to add capabilities to the language by certain amounts to build-in macro
Compiler:-
· Compiler is a translator program that translates a program written in (HLL) the source program and translate it into an equivalent program in (MLL) the target program.
· As an important part of a compiler is error showing to the programmer.

· Executing a program written n HLL programming language is basically of two parts. the source program must first be compiled translated into a object program.
· Then the results object program is loaded into a memory executed.

ASSEMBLER
· A mnemonic machine language is now called an assembly language. Programs known as assembler were written to automate the translation of assembly language in to machine language.
· The input to an assembler program is called source program, the output is a machine language translation (object program).
INTERPRETER
· An interpreter is a program that appears to execute a source program as if it were machine language.

· Languages such as BASIC, SNOBOL, LISP can be translated using interpreters. JAVA also uses interpreter. The process of interpretation can be carried out in following phases.
1. Lexical analysis
2. Syntax analysis
3. Semantic analysis
4. Direct Execution
Advantages:
· Modification of user program can be easily made and implemented as execution proceeds.
· Type of object that denotes various may change dynamically.
· Debugging a program and finding errors is simplified task for a program used for interpretation.
· The interpreter for the language makes it machine independent.
Disadvantages:
· The execution of the program is slower. Memory consumption is more.
LOADER AND LINK-EDITOR:
· Once the assembler procedures an object program, that program must be placed into memory and executed.
· The assembler could place the object program directly in memory and transfer control to it,
· System programmers developed another component called loader “A loader is a program that places programs into memory and prepares them for execution.”
· If subroutines could be translated into object form the loader could “relocate” directly behind the user’s program.
· The task of adjusting programs o they may be placed in arbitrary core locations is called relocation. Relocation loaders perform four functions.
TRANSLATOR
· Translator is a program that takes as input a program written in one language and produces as output a program in another language.
· The translator performs another very important role, the error-detection. Any violation of d HLL specification would be detected and reported to the programmers.
· Important role of translator are:
1) Translating the HLL program input into an equivalent ml program.
2) Providing diagnostic messages wherever the programmer violates specification of the HLL.
STRUCTURE OF THE COMPILER DESIGN
Phases of a compiler:
A compiler operates in phases. A phase is a logically interrelated operation that takes source program in one representation and produces output in another representation. The phases of a compiler are shown in below
There are two phases of compilation.
a. Analysis (Machine Independent/Language Dependent)
b. Synthesis(Machine Dependent/Language independent)
Compilation process is partitioned into no-of-sub processes called ‘phases’.

Lexical Analysis:-
· LA or Scanners reads the source program one character at a time, carving the source program into a sequence of atomic units called tokens.
Syntax Analysis:-
· The second stage of translation is called Syntax analysis or parsing. In this phase expressions, statements, declarations etc… are identified by using the results of lexical analysis.
· Syntax analysis is aided by using techniques based on formal grammar of the programming language.
Intermediate Code Generations:-
· An intermediate representation of the final machine language code is produced. This phase bridges the analysis and synthesis phases of translation.
Code Optimization:-
· This is optional phase described to improve the intermediate code so that the output runs faster and takes less space.
Code Generation:-
· The last phase of translation is code generation. A number of optimizations to reduce the length of machine language program are carried out during this phase.
· The output of the code generator is the machine language program of the specified computer.
Table Management (or) Book-keeping:-
· This is the portion to keep the names used by the program and records essential information about each. The data structure used to record this information called a ‘Symbol Table’.
Error Handlers:-
· It is invoked when a flaw error in the source program is detected. The output of LA is a stream of tokens, which is passed to the next phase, the syntax analyzer or parser.
·The SA groups the tokens together into syntactic structure called as expression. Expression may further be combined to form statements.
· The syntactic structure can be regarded as a tree whose leaves are the token called as parse trees.
Example

Regular languages:
· A regular language is a language that can be expressed with a regular expression or a deterministic or non-deterministic finite automata or state machine.
· A language is a set of strings which are made up of characters from a specified alphabet, or set of symbols. Regular languages are a subset of the set of all strings.
· Regular languages are used in parsing and designing programming languages

Operations on Regular Languages
· A regular language can be represented by a string of symbols and operations.
Concatenation
· Concatenation is an operation that combines two symbols, sets, or languages.
· There are two main ways to write a concatenation. X∘Y and XY both mean “X concatenated with Y.”
· Languages can also be concatenated: L1∘L2means strings from L1are written first, and then strings from L2come after.
Formally, concatenation is defined as follows: A∘B={xy ∣ x∈A and y∈B}.
Union
· Union is an operation where a finite state machine can make one choice or another at any step (this can also be thought of as an “or” operation). For example, there could be a finite state machine that can choose between concatenating X with Y or concatenating X with Z. Or is written with a vertical bar and the expression from the previous sentence looks like this: (X∘Y∣X∘Z).
Formally, union is described as follows: A∪B={x∣x∈A or x∈B}. Note, here the vertical bar means “such that.”
Kleene Star
· The Kleene star is an operation denoted by an asterisk ∗∗ that basically represents repeated self-concatenation.
· For example, if a language L represents all strings of the form ,X∗, then this language includes X, XX, XXXXXX, XXXXXXXXXXX, etc.
· The Kleene star can repeat the symbol it operates on any number of times.
· The regular language ∗X∘Y∣Z∗ represents strings of the form “X concatenated with Y or Z repeated any number of times.”
· Formally, the Kleene star is defined as follows: A∗={x1, x2…..xk |K≥0 and each A∗={x1,x2...xk∣k≥0 and each xi∈A}. The Kleene star is a unary operation since it operates only on one thing instead of two (unlike union and concatenation, which are binary operations).
Because k can be 0, x can be repeated 00 times. This means that the empty string is always a member of A∗.
The Empty String
Another important symbol is ϵ which represents the empty string.
FINITE AUTOMATON
· A recognizer for a language is a program that takes a string x, and answers “yes” if x is a sentence of that language, and “no” otherwise.
· We call the recognizer of the tokens as a finite automaton.
· A finite automaton can be: deterministic (DFA) or non-deterministic (NFA)
· This means that we may use a deterministic or non-deterministic automaton as a lexical analyzer.
· Both deterministic and non-deterministic finite automaton recognize regular sets.
· Which one?
– deterministic – faster recognizer, but it may take more space
– non-deterministic – slower, but it may take less space
– Deterministic automatons are widely used lexical analyzers.
· First, we define regular expressions for tokens; Then we convert them into a DFA to get a lexical analyzer for our tokens.
Non-Deterministic Finite Automaton (NFA)
· A non-deterministic finite automaton (NFA) is a mathematical model that consists of:
o S - a set of states
o Σ - a set of input symbols (alphabet)
o move - a transition function move to map state-symbol pairs to sets of states.
o s0 - a start (initial) state
o F- a set of accepting states (final states)
· ε- transitions are allowed in NFAs. In other words, we can move from one state to another one without consuming any symbol.
· A NFA accepts a string x, if and only if there is a path from the starting state to one of accepting states such that edge labels along this path spell out x.
Example
 |
· A Deterministic Finite Automaton (DFA) is a special form of a NFA.
· No state has ε- transition
· For each symbol a and state s, there is at most one labeled edge a leaving s. i.e. transition function is from pair of state-symbol to state (not set of states)
Example:
 |
Converting RE to NFA
· This is one way to convert a regular expression into a NFA.
· There can be other ways (much efficient) for the conversion.
· Thomson’s Construction is simple and systematic method.
· It guarantees that the resulting NFA will have exactly one final state, and one start state.
· Construction starts from simplest parts (alphabet symbols).
· To create a NFA for a complex regular expression, NFAs of its sub-expressions are combined to create its NFA.
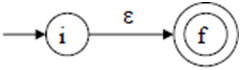 |
To recognize an empty string ε:

· To recognize a symbol a in the alphabet Σ:
 |
For regular expression r1 | r2:
N(r1) and N(r2) are NFAs for regular expressions r1 and r2.
· For regular expression r1 r2

 |
For regular expression r*
· Example:
· For a RE (a|b) * a, the NFA construction is shown below.
·
 |
·
Converting NFA to DFA (Subset Construction)
We merge together NFA states by looking at them from the point of view of the input characters:
· From the point of view of the input, any two states that are connected by an –transition may as well be the same, since we can move from one to the other without consuming any character. Thus states which are connected by an -transition will be represented by the same states in the DFA.
· If it is possible to have multiple transitions based on the same symbol, then we can regard
a transition on a symbol as moving from a state to a set of states (ie. the union of all those states reachable by a transition on the current symbol). Thus these states will be combined into a single DFA state.
To perform this operation, let us define two functions:
· The -closure function takes a state and returns the set of states reachable from it based on (one or more) -transitions. Note that this will always include the state itself. We should be able to get from a state to any state in its -closure without consuming any input.
· The function move takes a state and a character, and returns the set of states reachable by one transition on this character.
Scanner Generator
 |
Lex specifications:
A Lex program (the .l file ) consists of three parts:
declarations
%%
translation rules
%%
auxiliary procedures
1. The declarations section includes declarations of variables, manifest constants(A manifest constant is an identifier that is declared to represent a constant e.g. # define PIE 3.14), and regular definitions.
2. The translation rules of a Lex program are statements of the form
p1 {action 1}
p2 {action 2}
p3 {action 3}
… …
… …
Where, each p is a regular expression and each action is a program fragment describing what action the lexical analyzer should take when a pattern p matches a lexeme. In Lex the actions are written in C.
3. The third section holds whatever auxiliary procedures are needed by the actions. Alternatively these procedures can be compiled separately and loaded with the lexical analyzer.
0 Comments